llms.txt 是什麼?讓 AI 找到你網站的關鍵 5 分鐘設定
TL;DR
- llms.txt 是 2024 年由 Jeremy Howard 提案的新標準,放在網站根目錄,給 AI 搜尋引擎一份「網站結構索引」,讓 LLM 能更精準找到要引用的內容。
- 它不是 robots.txt 的替代品,而是補位——robots.txt 管「允不允許爬」,llms.txt 管「該優先看哪些」。兩個檔案職責不同,網站該同時放。
- 格式極簡,5 分鐘能寫完——Markdown 寫,首段一句話描述網站、中間用 H2 分類列重要連結,完成度比第一次寫 sitemap 還低。
- 目前不是強制標準,但採用速度比預期快——Anthropic、Cloudflare、Vercel 等公司都已放上自家的 llms.txt,部分 AI 工具開始解析這份檔案做為內容索引。
一、llms.txt 是什麼?為什麼一個 2024 年的提案突然變成 GEO 必做項目?
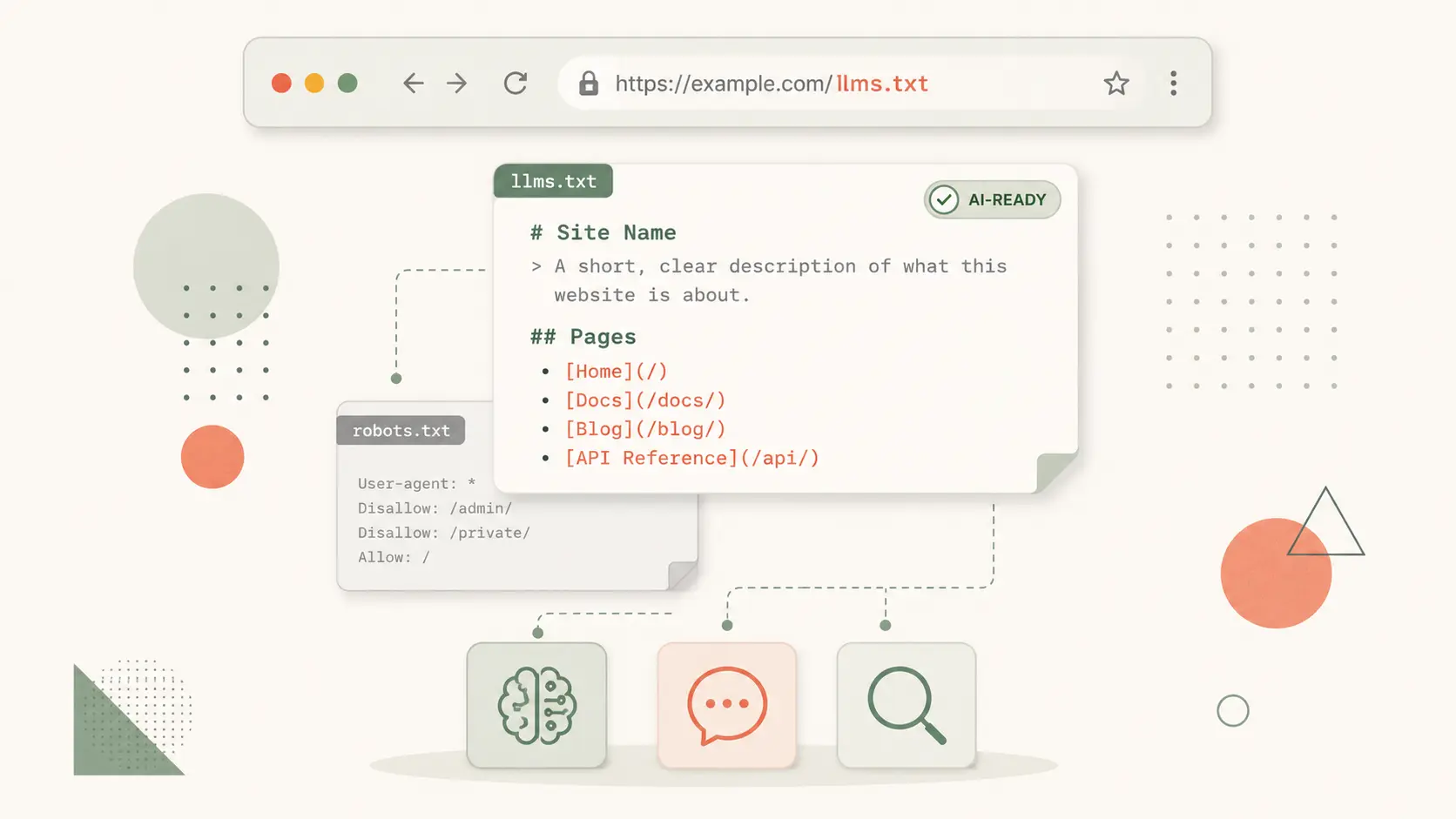
核心觀點: llms.txt 是放在網站根目錄的 Markdown 檔案,作用是告訴大型語言模型(LLM)「這個網站的內容地圖長這樣,優先讀這些頁面」。它在生成式 AI 搜尋時代的角色,類似 sitemap.xml 在傳統 SEO 時代的地位——讓機器更快找到結構化的內容入口。
llms.txt 由 Answer.AI 創辦人 Jeremy Howard 在 2024 年 9 月提出,目的是解決一個實務問題:LLM 在引用網頁內容時,需要從充滿 navigation、廣告、彈窗、CSS 的完整 HTML 中萃取「真正的內容」,這個過程容易出錯。如果網站直接提供一份精簡、用 Markdown 寫的內容地圖,LLM 引用的準確度會大幅提升。
這份檔案放在網站根目錄 https://yoursite.com/llms.txt,內容是 Markdown 格式。第一段用一句話描述網站性質,接著用 H2 分類列出重要頁面連結與每個頁面的簡短說明。整份檔案通常不超過幾百行,寫起來比 sitemap.xml 還快。
提案推出後,Anthropic、Cloudflare、Vercel、Netlify、Hugging Face 等公司陸續在自家網站放上 llms.txt,部分 AI 工具與爬蟲也開始將這份檔案納入解析流程。雖然目前還不是 W3C 或 Google 官方標準,但採用速度比一般「新提案」快得多——這在 GEO(Generative Engine Optimization)策略中代表「低成本、高潛在報酬」,值得在早期就佈署。
完整的 GEO 策略地圖可參考 SEO 與 GEO 完整指南;llms.txt 是其中「AI 友善基礎建設」這一層最容易實作的入口。
二、llms.txt 跟 robots.txt 差在哪?兩個檔案要同時放嗎?
核心觀點: robots.txt 是「黑名單機制」,告訴爬蟲哪些路徑禁止抓取;llms.txt 是「白名單推薦」,告訴 LLM 哪些頁面是網站的核心內容。前者管「允不允許」,後者管「優先看哪些」。兩個檔案職責互補,網站應該同時放,不需要二選一。
robots.txt 已存在 30 年以上,是搜尋引擎爬蟲的標準守則。它的語法簡單:User-agent: * 後接 Allow: 或 Disallow: 路徑。這份檔案的角色是「設邊界」——告訴爬蟲哪裡能去、哪裡不能去。對 AI 爬蟲(如 GPTBot、ClaudeBot、PerplexityBot)的允許與否,也是透過 robots.txt 控制。
llms.txt 的設計目的完全不同。它不是用來「擋」爬蟲,而是「導引」LLM 找到內容入口。一個典型 llms.txt 會列出:
- 網站主要產品/服務頁面
- 重要部落格分類或熱門文章
- 文件、API reference 或使用手冊
- 公司介紹、聯絡方式
LLM 在引用網站時,可以先讀這份檔案,從中決定要進一步抓哪些頁面。這對內容多、結構深的網站特別有幫助——LLM 不必盲爬全站,就能找到「網站作者覺得重要的東西」。
兩個檔案的職責沒有重疊,實務上建議都放。robots.txt 控制 AI 爬蟲的存取權限(是否允許 GPTBot 索引),llms.txt 則在允許存取後告訴它「該優先看哪些」。
實作上還有一個進階版本 llms-full.txt,放網站「完整內容濃縮版」(把所有重要頁面內容直接展開在一份檔案裡,LLM 不必再去抓子頁)。這個版本適合文件型網站、教學型部落格,商家網站通常用 llms.txt 就夠。
三、llms.txt 的格式長什麼樣?5 分鐘能寫出來的核心結構
核心觀點: llms.txt 的格式刻意設計成「Markdown 最低語法」——第一行用 H1 寫網站名稱、第二行用引用區塊寫網站一句話描述、之後用 H2 分類列重要連結。整份檔案沒有 schema、沒有 XML,任何能寫 README 的人都能上手。
一份標準 llms.txt 的骨架如下:
# 網站名稱
> 用一句話描述網站性質、目標受眾、核心價值。
## 核心頁面
- [首頁](https://example.com/): 首頁說明
- [關於我們](https://example.com/about): 公司或品牌簡介
- [服務](https://example.com/services): 主要服務項目
## 部落格分類
- [SEO 教學](https://example.com/blog/category/seo): 給商家的 SEO 與 GEO 操作指南
- [行業案例](https://example.com/blog/category/cases): 不同行業的網站經營參考
## 重要文章
- [Schema.org 是什麼](https://example.com/blog/schema): 結構化資料入門
- [GEO 完整指南](https://example.com/blog/geo-guide): AI 搜尋優化策略
幾個寫作要點:
第一,每一條連結後加一句說明——LLM 不只看 URL,還會看說明文字判斷該頁的內容主題。說明應該寫得像「這頁在講什麼」,而不是 SEO 關鍵字堆疊。
第二,只列重要頁面,不要全站塞進來。llms.txt 的價值在於「精選」,把全站連結都丟進去等於沒有索引。商家網站通常列 10–30 個連結已經夠用。
第三,H2 分類用直覺命名。「核心頁面」「部落格分類」「重要文章」「使用文件」這類分類比「Resources」「Misc」更利於 LLM 理解網站結構。
第四,手寫一次,後續用工具同步。第一份 llms.txt 建議手寫,確認分類邏輯與描述語氣;之後可用工具自動產生,避免每次新增頁面都要手動更新。AHHA llms.txt 產生器 可以直接輸入網站結構產出符合規範的檔案內容,免登入、瀏覽器本地運算。
四、哪些 AI 搜尋引擎已經在讀 llms.txt?
核心觀點: 目前主流 AI 引擎尚未公開「正式採用 llms.txt 作為索引依據」,但生態系的採用速度超出多數新提案的常態。對網站擁有者而言,實作成本極低、潛在收益不對稱,屬於「先做再說」的低風險投資。
關於 llms.txt 的實際使用狀況,業界目前可觀察到的訊號分三類:
第一類:大型科技公司主動採用。 Anthropic、Cloudflare、Vercel、Netlify、Hugging Face、Stripe 等公司都已在自家網站根目錄放上 llms.txt。對技術社群而言,這些公司的採用本身就是強訊號——它們不會在沒有實際效益預期的情況下加上新檔案。
第二類:AI 工具開始解析這份檔案。 部分文件查詢工具、開發者助手已將 /llms.txt 加入解析流程,在使用者查詢某網站內容時優先讀這份檔案。可預期主流 AI 搜尋引擎(ChatGPT、Perplexity、Gemini)會跟進,但具體時程未公開。
第三類:Anthropic 的 Claude 已在文件中提到 llms.txt 標準,作為「AI 友善網站」的最佳實踐之一。這個來源可信度高,代表至少 Anthropic 體系內的 LLM 會逐步把 llms.txt 納入內容理解流程。
對網站擁有者而言,實作 llms.txt 的成本約是 5–30 分鐘(看網站規模),而潛在收益是「被 AI 引擎更精準引用」。即使最後標準沒有大規模採用,放這份檔案也不會傷害 SEO 或 GEO——它純粹是「多一個入口給 AI」。這種風險與報酬不對稱的情境,是早期佈署的標準時機。
五、怎麼確認你的 llms.txt 是否設定正確?
核心觀點: llms.txt 沒有官方驗證工具,但有三個務實的檢查方式:HTTP 200 可訪問、Markdown 語法正確、AI 爬蟲爬取狀態正常。前兩項自己看,第三項需要工具輔助。
llms.txt 不像 Schema.org 有官方 validator,也不像 robots.txt 有 Google Search Console 的「robots.txt 測試工具」。但要驗證設定是否正確,有三件事可以做:
第一件:確認檔案存在且可訪問。 在瀏覽器直接打 https://yoursite.com/llms.txt,應該回 HTTP 200 並顯示 Markdown 內容。如果回 404 或 403,代表檔案沒上線或路徑錯誤。許多平台需要手動將 llms.txt 加入「允許靜態檔案路徑」白名單,值得提前確認。
第二件:檢查 Markdown 語法。 把 llms.txt 內容貼到任何 Markdown 預覽工具(如 GitHub Gist、Dillinger),確認 H1、H2、引用區塊、列表、連結都正確渲染。語法錯誤的 llms.txt 對 LLM 等同無效——它讀到一團爛掉的文字,反而可能誤判網站性質。
第三件:檢查 AI 爬蟲允許性。 llms.txt 的價值前提是 AI 爬蟲能爬到你的網站。如果 robots.txt 把 GPTBot、ClaudeBot、PerplexityBot 全擋了,llms.txt 寫得再漂亮也沒用。
AHHA SEO + GEO + AI 爬蟲三合一檢測 會自動掃描網站的 llms.txt 是否存在、robots.txt 對 7 種主流 AI 爬蟲的允許狀態、Schema.org 標記是否完整,並產出對照清單。對於剛實作 llms.txt 的網站,這個工具能在一次檢測中確認所有 GEO 友善訊號是否到位。
關於 Schema.org 的部分,可以延伸閱讀 商家網站最該做的 5 種結構化資料——llms.txt 與 Schema.org 是 GEO 兩條互補的腿,前者管「網站結構索引」,後者管「個別頁面語意」,兩者搭配效果最好。
六、結語:llms.txt 是低成本高槓桿的 GEO 早期紅利
llms.txt 是少數「實作成本極低、潛在收益不對稱」的 GEO 工具。對網站擁有者而言,寫一份不到一頁的 Markdown 檔案、放到根目錄,可能就是「未來 AI 搜尋時代被精準引用」與「被 LLM 忽略」之間的差別。
新標準的採用通常經歷三個階段:技術社群試水、大公司導入、主流工具支援。llms.txt 目前處於第二階段尾聲——Anthropic、Cloudflare、Vercel 等公司已採用,主流 AI 搜尋引擎的支援只是時間問題。在這個時點放上 llms.txt,等於提前佔位,讓網站在 AI 引擎開始大規模解析這份檔案時已經在「先到先看」的名單裡。
實作 llms.txt 不需要工程能力,但需要對網站結構有清楚的判斷——哪些頁面是核心、哪些只是周邊。可以用 AHHA llms.txt 產生器 快速產出初版,再依網站實際情況微調。完整檢測整站 GEO 設定可用 SEO + GEO + AI 爬蟲三合一檢測。AI 搜尋時代下 robots.txt 與 llms.txt 為何同時成為基本門檻,可進一步參考 AI 搜尋時代企業還需要做網站嗎 與 如何讓 AI 引用你的品牌:3 個有數據支持的做法。
如果想直接使用一個內建 llms.txt 自動產生、Schema.org @graph 完整實作、robots.txt 預設允許主流 AI 爬蟲的網站平台,可以 立即試用 AHHA 30 天 →。
常見問題
llms.txt 是什麼?跟 robots.txt 不一樣嗎?
llms.txt 是 2024 年由 Jeremy Howard 提出的網站結構索引檔案,放在網站根目錄,用 Markdown 寫,告訴大型語言模型(LLM)這個網站的重要內容入口。它跟 robots.txt 職責完全不同:robots.txt 是「黑名單」,管哪些路徑禁止爬取;llms.txt 是「白名單」,推薦 LLM 優先讀哪些頁面。實務上兩個檔案應該同時放。
llms.txt 是強制標準嗎?不放會怎樣嗎?
目前不是強制標準,也不是 W3C 或 Google 官方規範。不放 llms.txt 不會傷害 SEO 或既有 GEO 訊號。但採用速度比一般新提案快,Anthropic、Cloudflare、Vercel 等公司都已部署,部分 AI 工具開始解析這份檔案。實作成本約 5–30 分鐘,潛在收益是被 AI 引擎更精準引用——屬於風險與報酬不對稱的早期紅利。
llms.txt 跟 sitemap.xml 是同一回事嗎?
角色類似但對象不同。sitemap.xml 是給傳統搜尋引擎爬蟲(Googlebot)看的全站連結清單,格式是 XML、列所有頁面、不帶說明。llms.txt 是給 LLM 看的精選內容索引,格式是 Markdown、只列重要頁面、每條連結加一句說明文字。兩個檔案應該都放,給不同的機器讀。
llms.txt 該列多少個連結?整站還是只列重點?
只列重點。llms.txt 的價值在於「精選」——告訴 LLM「網站作者覺得這幾個頁面最重要」。商家網站通常列 10–30 個連結就夠了,包含首頁、主要服務、重要部落格分類與熱門文章。把全站連結都塞進去等於沒有索引,反而讓 LLM 失去判斷依據。
llms-full.txt 跟 llms.txt 差在哪?兩個都要放嗎?
llms.txt 是「索引」,列出重要頁面的 URL 與簡短說明,LLM 看了再決定要不要抓子頁。llms-full.txt 是「完整內容濃縮版」,把所有重要頁面內容直接展開在一份檔案裡,LLM 不必再爬子頁。前者適合所有網站,後者適合文件型網站、API reference、教學型部落格。商家網站通常只需要 llms.txt。
怎麼確認我的 llms.txt 設定正確?有官方驗證工具嗎?
目前沒有官方驗證工具,但可以做三件事:1)打開 yoursite.com/llms.txt 確認回 HTTP 200 且顯示 Markdown;2)把內容貼到 Markdown 預覽工具確認語法正確;3)檢查 robots.txt 是否允許 GPTBot、ClaudeBot、PerplexityBot 等 AI 爬蟲存取網站。AHHA 的 SEO + GEO + AI 爬蟲三合一檢測會一次涵蓋這三項。
SEO 與 AI 搜尋 分類其他文章
繼續閱讀同主題的延伸內容
留言討論
只有會員能留言(防止垃圾訊息),留言顯示於此頁。